

Building an Azure-Native Data Mesh to Empower Microsoft Customers
Published August 8, 2023 Last Updated on October 23, 2025

In a previous blog, we talked about the data mesh as an enabler for AI-driven companies. In this blog we describe how we built the Ontinue ION data mesh, the foundation of ION IQ for rapid AI skill development, using Azure services and resources.
Challenges and Design Choices
Implementing the data mesh can prove quite challenging in practice. While its theoretical principles resonate well and do drive a high-level logical architecture, they do not suggest an actual design and leave the implementation details up to interpretation. In fact, several architectures have been proposed to date.
When implementing the data mesh, it is essential to consider your organization’s particular setup, existing technology stack, budget, internal structure, and level of agility, and to make realistic design choices that favor simplicity.
To the delight of many organizations, all major cloud providers have recently embraced the data mesh design patterns. Microsoft, more than others, is continuously developing its Azure analytics services, tooling, and documentation towards drastically simplifying and accelerating data mesh implementations.
Data domains
The first critical step, and the one most people struggle with, is to define the business domains and their boundaries. A common approach is to first define a domain conceptually and then staff it with a team. This approach often involves an enormous reorganization effort, making it too impractical to implement. Instead of treating each service delivery team and business unit as a separate domain, we recommend defining data domains. That is, domains into which the organization’s data products can be conceptually grouped together.
For example, we consider all data products related to security operations as one data domain. Customer environment and vulnerability management are other examples of data domains. Each team can produce data products that belong to different domains, using dedicated team resources and their own processes. Each team’s tech lead naturally acts as the data product owner of the data products the team produces and maintains.
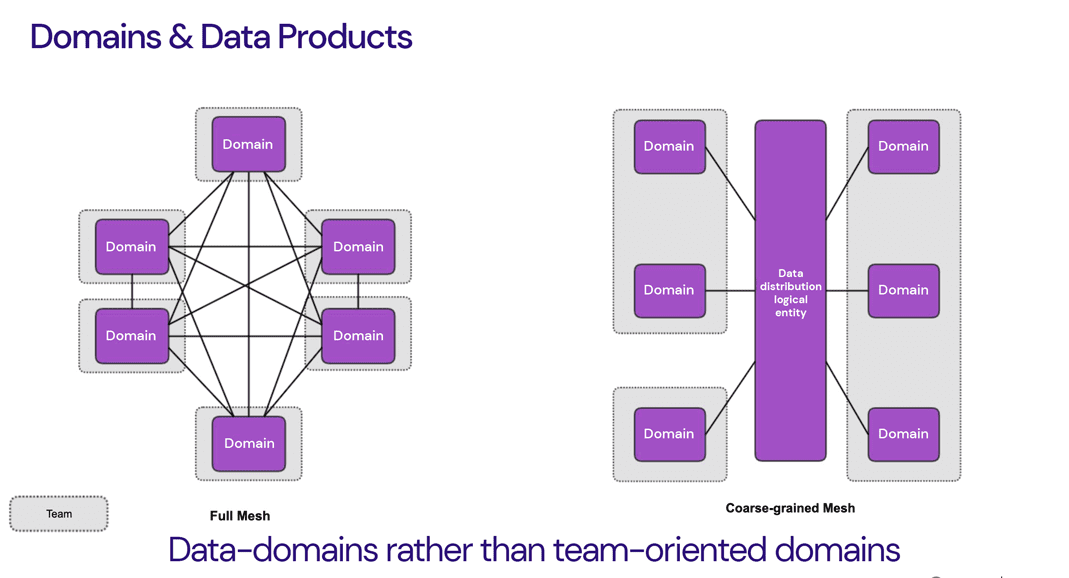
Full vs. coarse-grained mesh
A full mesh topology, i.e., serving the analytical data from the perimeter of each domain, assumes a high level of maturity in data product design, provisioning and sharing within every team. This might be unrealistic in practice.
For ION data mesh, we adopt a coarse-grained mesh implementation where domains distribute their analytical data products via a central logical entity that serves as a single source of truth. It is built on top of the Azure Data Lake Storage Gen2 (ADLSg2), leveraging its scalability and performance capabilities, together with a custom access control model based on Microsoft Entra ID. Data products are stored in the highly optimized Delta format, each with a data contract that ensures consumers can understand and trust them.
This design strikes a good balance between decentralization and centralization. Decentralized domains still own the data products they produce and can control how others access them. And it is centralized sufficiently to make it easier to run continuous quality and interoperability checks, automate policies, enable easy data product discovery and aggregation, and adopt a uniform way of working among teams.
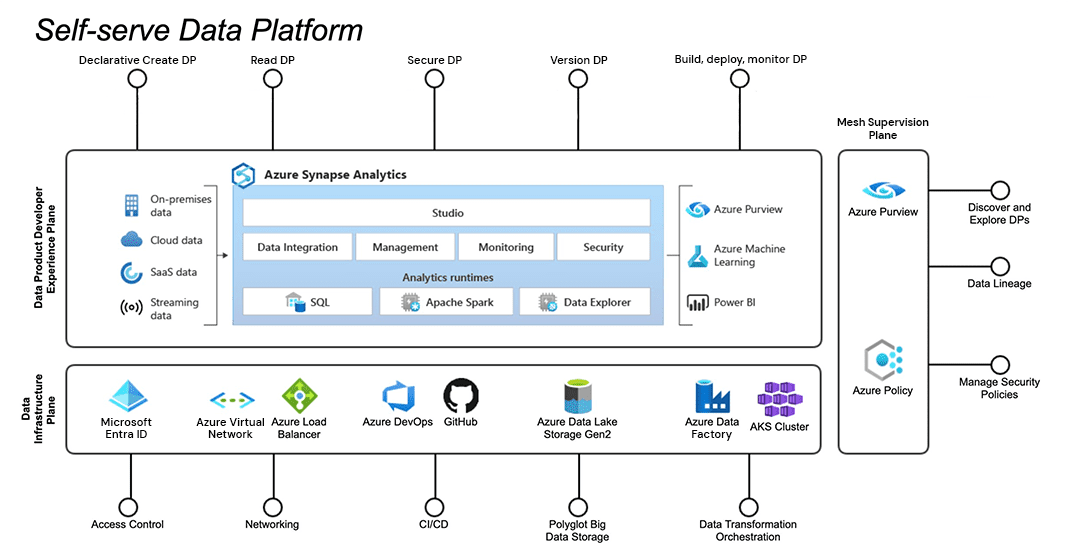
Self-serve data platform
The self-serve platform — and its ability to abstract complexity — is a crucial piece of the data mesh. Azure Synapse is an analytics service that provides the necessary abstractions and tooling so that any team, even those without data engineers, can independently build, deploy, and monitor their own data products. It provides declarative interfaces to:
- seamlessly connect to operational data sources
- use existing data products
- create and manage compute resources (e.g., Spark pools)
- build and orchestrate pipelines for data integration and ETL/ELT
- integrate with services such as Power BI and AzureML
Azure Synapse practically implements the data product developer plane, as defined by the data mesh principles. It also abstracts from the user the underline Azure infrastructure – the data infrastructure plane – needed to perform all those complex operations. Each team uses and is responsible for their own Synapse instance and relevant cloud resources.
Enabling team
Ideally, an organization would have an enabling team staffed with data and AI experts to accelerate the data mesh adoption and increase data maturity across the organization. Our ION IQ enabling team provides data product design guidelines, data pipeline creation examples and blueprints, Terraform templates and GitHub workflows for automatic deployment of pre-configured analytics resources, tutorials, and best-practice articles. All of these help other teams to autonomously produce and consume data products. Most importantly, our enabling team designed and maintains a mature ML Ops paradigm, baked into the data platform, that allows any team to train and operationalize machine models (or use pre-trained ones) with AzureML and Azure OpenAI service.
Unified data governance
For implementing a mesh supervision plane, we heavily rely on Microsoft Purview and its valuable out-of-the-box features: business glossary definition, automatic data discovery, data lineage, sensitive data classification and automatic alerting on data policy violation, to name just a few. Having 365-degree visibility on our data product estate not only allows for running continuously and effectively interoperability, privacy, and compliance checks, but also for having complete control over which data is used for training in-house expert machine learning models and for fine-tuning pre-trained ones, such as Large Language Models (LLMs).
Supercharging Cyber Defenders
The ION data mesh allows for gathering and correlating high-quality and trustworthy data – the ION IQ data – from various sources that can be used to train powerful expert machine learning models. These empower our Cyber Defenders by providing unique insights and recommendations that can increase their efficiency.
For example, by analyzing the triage steps of past incidents for a given customer, along with their critical asset behavior patterns and other customer environment-specific information – all as data products in the Ontinue ION data mesh – our expert machine learning models can predict which incidents are more likely to be true positives. Our Cyber Defenders can prioritize these and immediately start further analysis, instead of handling potential benign positives first.

Iris Safaka is Principal Data Scientist for Ontinue and has more than 10 years of experience working in cybersecurity, machine learning and analytics. She has published scientific papers for top security venues, actively serves as member of Technical Program Committees, participates on expert panels on AI, data and security, and has been invited to give talks at USENIX, IEEE and ACM. Iris earned a PhD in computer and communication sciences from the Swiss Federal Institute of Technology (EPFL).


