

Designing an MLOps platform: Insights from the Ontinue Data Science Team
Published January 13, 2025 Last Updated on October 23, 2025
In a previous post, we discussed the most common challenges that organizations face when trying to operationalize ML and how MLOps addresses them. This post goes into the technical details of Ontinue’s MLOps platform, which was designed using the principles discussed in our previous post. The Ontinue MLOps platform powers ION IQ, the AI that underpins our ION MXDR service.
Simplifying connectivity and reducing costs with an Azure native approach
Ontinue’s data platform, just like the ION technology platform itself, is primarily built using Azure native services. This simplifies the required connectivity and decreases the cost to access data.
Azure’s native solution for building and deploying machine learning models is Azure Machine Learning (Azure ML). This service has recently been extended with pretrained foundation models and tools to build Generative AI solutions. In this post we will focus purely on training machine learning models.
Easy access to increased compute power with Azure ML development environment
Azure ML includes a hosted development environment with a rich set of features for data scientists. Included in this online “studio” is a Jupyter Notebook editor, which allows our data scientists to use a familiar tool while running their code on managed compute instances that are more powerful than most data scientists’ workstations. For those whoprefer an integrated development environment (IDE), it is possible to connect to the compute instances from VS Code using the “Azure Machine Learning – Remote” extension.
As detailed in our previous post, Jupyter Notebooks are excellent for initial exploration. But as the amount of code grows, we want to refactor the cells into functions and modules that can be reused across our code. Finding a good project structure can be a challenge. Luckily this is made easier by using a Cookiecutter template that is best suited for your ML project.
Abstracting data management and configuration with the Kedro framework
We went a step further and adopted the Kedro framework, which not only provides project templates, but also abstracts the management of data and configuration, and commands for running (parts of) our code. This Kedro functionality can also be accessed from within Jupyter notebooks, so we can build our exploration on top of results from refactored code.
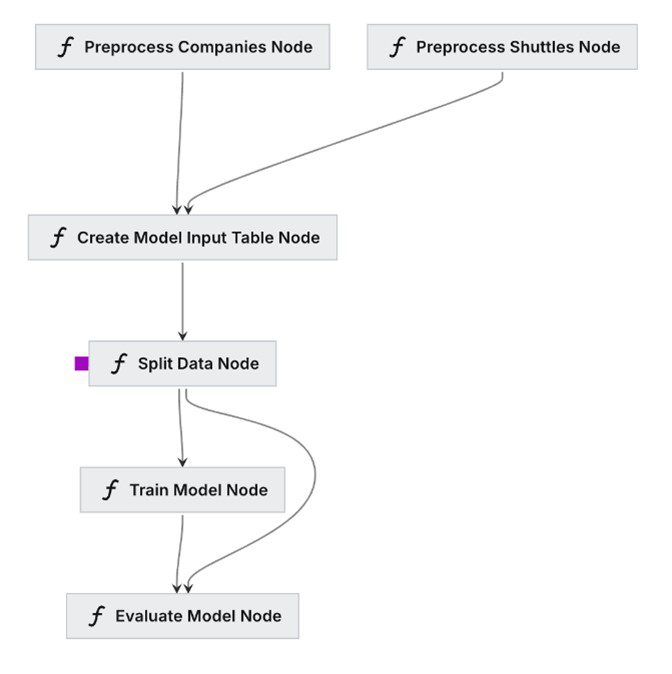
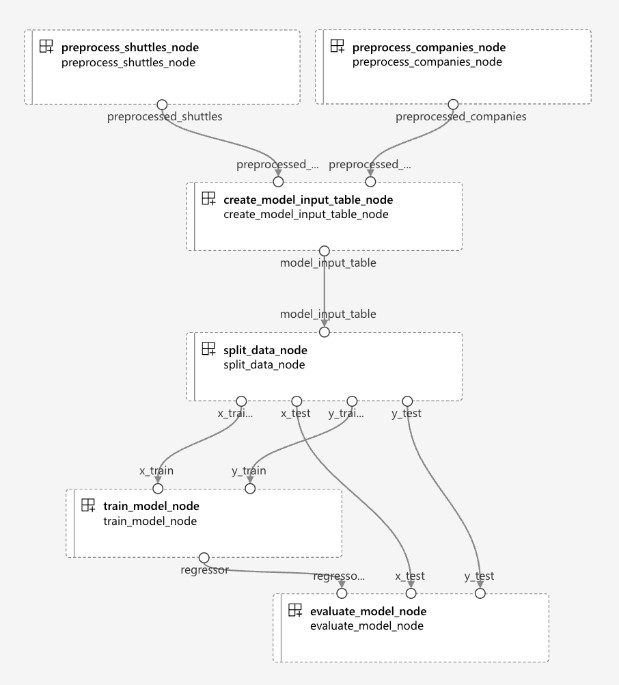
A Kedro pipeline (left) and its equivalent in Azure ML (right)
Experiment tracking & reproducibility with MLflow
By using nodes and pipelines to structure our training code, the code can be run on any compute target supported by Kedro or one of its many plugins. At Ontinue, we use and contribute to the kedro-azureml plugin, which translates Kedro pipelines into their Azure ML equivalents and adds support for using Azure ML Data Assets in the Kedro Data Catalog. The importance of this cannot be understated: with a simple substitution of the command “kedro run” by “kedro azureml run”, our code is submitted as an Azure ML Job without having to worry about any of the boilerplate that is normally necessary to create these jobs. This saves us considerable time and effort.
When it comes to experiment tracking, MLflow is hard to beat. It provides functionality to log metrics, parameters and artifacts for every run of your code. While it can be used locally, we mainly use it on Azure ML, since that allows the whole team to access the results. Because Azure ML natively supports MLflow, it is possible to compare the results of different experiments in the Azure ML Studio, while simultaneously allowing us to reproduce those results. This is because all the information about code, dependencies, parameters and input data is saved in the same place.
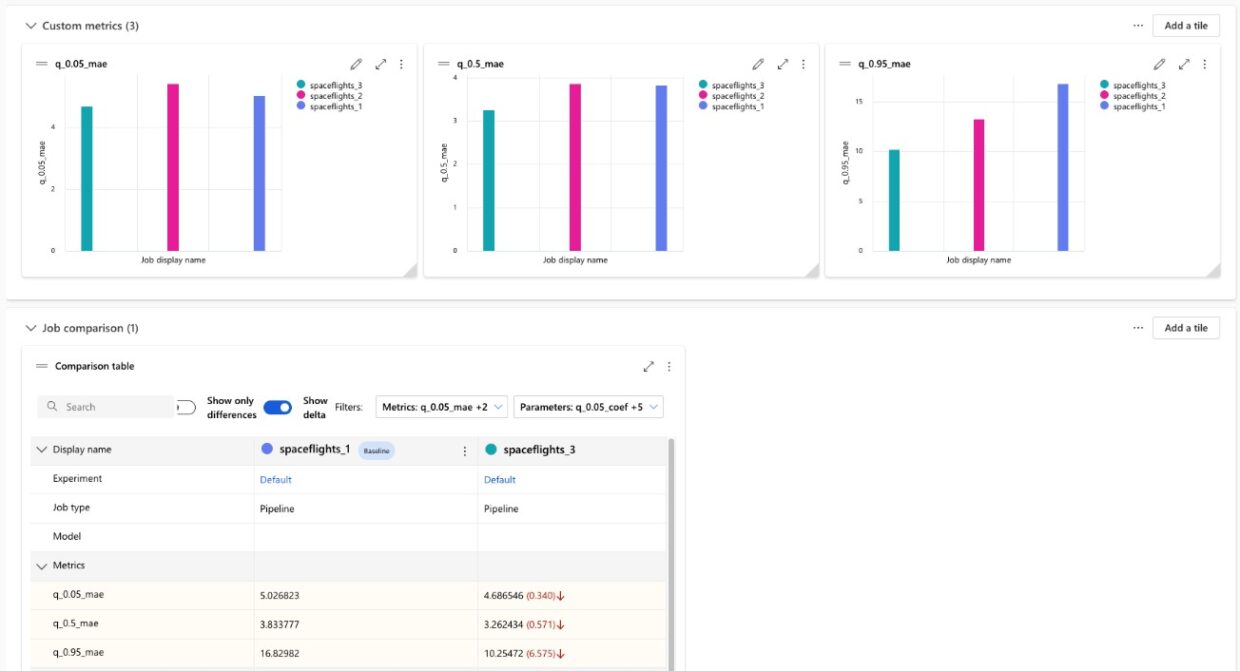
Comparison of metrics between different jobs in Azure ML
Traceability & automation using Azure ML & GitHub Actions
The same functionality that allows us to reproduce experiments, also enables us to know exactly how the models we deploy to production were obtained. By registering the model in the Azure ML Model Registry, a link to the job that generated it is added to the model’s metadata allowing us to track exactly which job created which model. To eliminate any errors that could arise from manually submitting these jobs, we use a GitHub Actions workflow to automatically create the job when the code is merged in our repository. For models that need regular retraining, our CI/CD workflows create an Azure ML Schedule for the training job.
Before integrating new code into the repository, it is crucial to test it as thoroughly as possible. Apart from running unit tests, our CI system also submits a job to Azure ML with the code changes. This allows the code reviewers to check whether the code behaves as expected in a realistic environment.
Model deployment & monitoring using Azure ML & GitHub Actions
Our models are deployed using Azure ML Managed Online Endpoints, which integrates seamlessly with the Model Registry and eliminates the need to manage the infrastructure for running the model endpoints. Depending on the project, the latest model in the Model Registry is deployed automatically using a GitHub Actions cron job. The latency of the model is monitored using Azure Monitor. Our model predictions are stored on our data platform so they can be analyzed by Synapse pipelines and visualized using Power BI dashboards. This enables data scientists to detect any drift in the predictions and adapt the code if necessary.
Designing an MLOps platform for your organization
The Ontinue MLOps platform is the best platform we could build given our desire to be Azure native, use state-of-the-art tools, and operate within our organization’s constraints. However, the use cases and constraints are different in every organization and these should be considered when designing your platform. We think it’s essential to start from the MLOps principles, which will likely imply using an ML framework, an experiment tracking tool and a model registry. If you make sure these support your ML use cases and can be integrated with your data platform and CI/CD tool, the remaining technical choices will mostly be a matter of preferences. Good luck designing your MLOps platform!

Tomas Van Pottelbergh is a Senior Data Scientist at Ontinue with more than 4 years of experience as a data scientist in the Energy, Banking, Chemical and Cybersecurity sectors. He has published in JMLR and Neural Computation, and contributed to open-source data science packages such as Darts and kedro-azureml. Tomas earned a PhD in Engineering from the University of Cambridge, where he worked on mathematical modelling of biological neurons.



