

Unlocking the Potential: Operationalizing Machine Learning
Published January 24, 2024 Last Updated on October 23, 2025

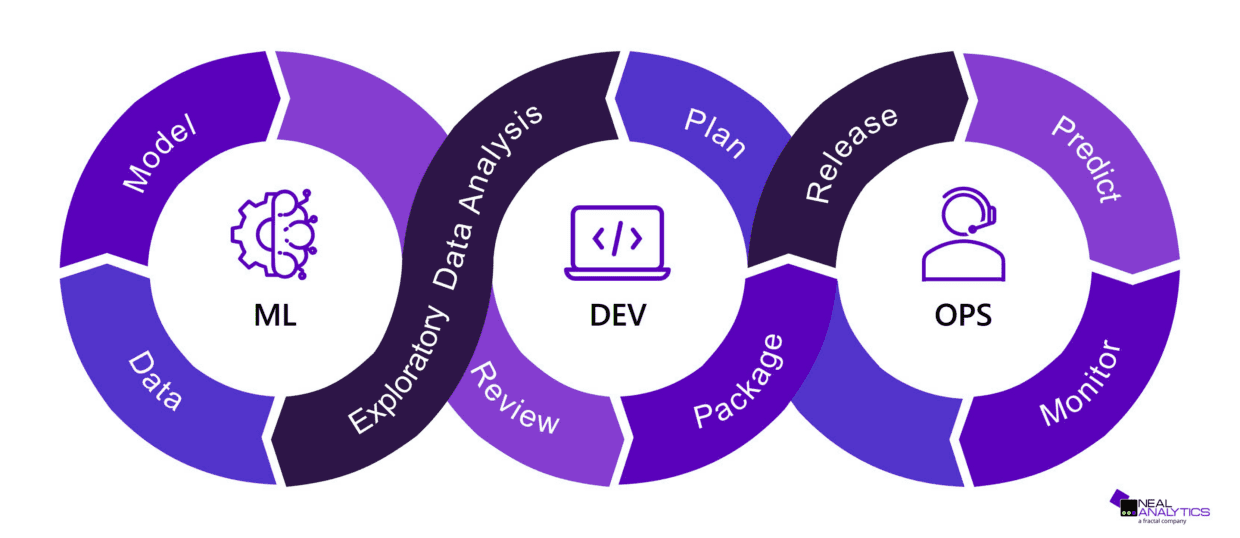
With more and more companies eager to tap into machine learning’s potential for revolutionizing decision-making, optimizing operations, and unearthing valuable insights, it has become increasingly important for organizations to learn how to operationalize machine learning. Thanks to user-friendly solutions like AutoML, the entry barrier for using machine learning has significantly dropped. However, fully operationalizing ML is a journey; from navigating the complexities of moving from experimental to production-grade models, to ensuring robust experiment tracking and reproducibility, there are many hurdles to overcome. That’s where Machine Learning Operations, or “MLOps”, comes in. MLOps is a set of practices designed to streamline the ML development process and overcome these challenges to ensure a smooth integration of ML into everyday business operations. What follows is a list of the most common challenges that organizations face when trying to operationalize ML and a discussion of how MLOps addresses them.
1) Transitioning from experimental to production-ready code
Many data scientists love the flexibility of Jupyter Notebooks for exploratory data analysis. Yet, beyond initial data exploration, developing robust production-ready code in notebooks quickly becomes challenging. Transitioning from notebooks to a more comprehensive integrated development environment (IDE) will make it easier to test, refactor and review the code to make it ready for production. Embracing ML frameworks can further streamline the development process, eliminating the need to reinvent the wheel with custom configuration parsers and pipeline runners. ML frameworks also help create a common structure between projects.
2) Simplifying experiment comparison
The iterative nature of ML model development demands extensive experimentation, from feature engineering to hyperparameter tuning. The goal of these experiments is to choose whether to use a certain feature, transformation, algorithm, or select the best value for a hyperparameter according to some metrics (usually model performance, but sometimes also resource usage). Without a proper tracking system, comparing these experiments can be a time-consuming task. Experiment tracking tools are invaluable allies that offer a structured approach to log multiple metrics and analyze them, often via a simple user interface. This enables data scientists to make informed choices during model development.
3) Ensuring reproducibility
The ability to reproduce successful experiments is paramount for putting machine learning models into production environments. Without experiment reproducibility, the team cannot be confident that similar results can be obtained when the model needs to be retrained. Tracking metrics is just the starting point; meticulous documentation of versioned datasets, code, libraries, and configuration parameters is also essential. While the code, library versions and configuration parameters can be stored in a version control system, versioning datasets requires a different approach which is often offered by ML frameworks or platforms.
4) Keeping track of the origin of your model in production
Even with robust tracking mechanisms in place, the origin of a model in production remains obscured without metadata. This means auditing the model, debugging it, or improving its performance becomes hard, or even impossible. Experiment tracking tools that are equipped with a model registry bridge this gap by associating the model with the experiment that produced it. This transparency ensures clarity on the dataset, code, and libraries that resulted in the production model.
5) Automating training and deployment
While model registration addresses traceability, manual initiation of model training introduces extra effort and potential mistakes. This can discourage engineers from retraining the model on more recent data, resulting in sub-optimal model performance in production. Drawing inspiration from DevOps practices, automating builds, deployments, and training runs becomes key to keep the model up to date. These automations can be triggered by events such as code changes, or on a schedule.
6) Avoiding performance degradation using monitoring
The deployment journey doesn’t end with automation. As models operate in production, changes in input data properties may occur, requiring updates to training code or configurations. Detecting these shifts entails careful monitoring of inference data. ML platforms equipped with data monitoring tools offer a vigilant eye on potential drifts, ensuring sustained model performance.
The challenges in operationalizing ML mirror and extend the complexities in classical software development. Embracing a holistic approach, akin to the principles of DevOps, becomes indispensable. In a follow-up post we will shed light on our ION IQ MLOps platform, which can serve as inspiration for implementing MLOps in your organization.

Tomas Van Pottelbergh is a Senior Data Scientist at Ontinue with more than 4 years of experience as a data scientist in the Energy, Banking, Chemical and Cybersecurity sectors. He has published in JMLR and Neural Computation, and contributed to open-source data science packages such as Darts and kedro-azureml. Tomas earned a PhD in Engineering from the University of Cambridge, where he worked on mathematical modelling of biological neurons.



