Ein technischer Einblick in den ION IQ Bot
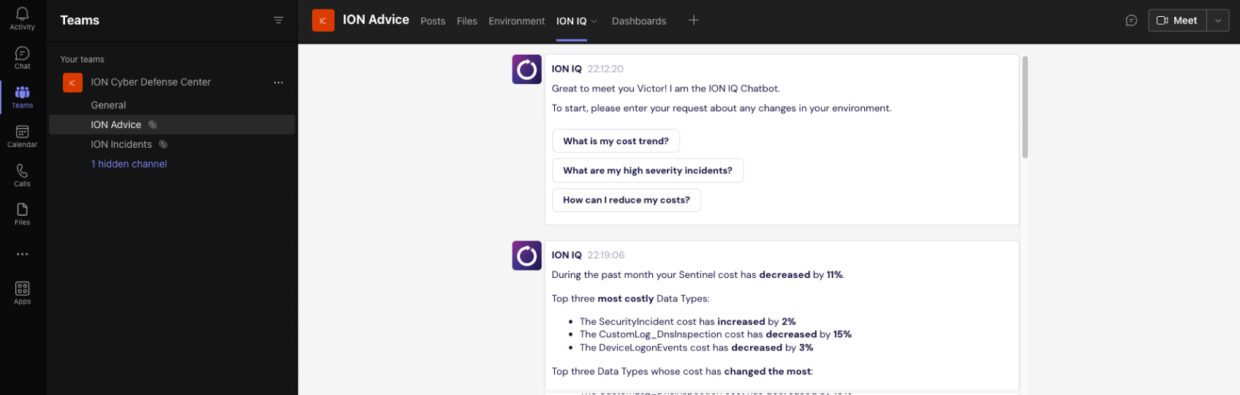
Wie bereits in der vorheriger Beitrag in unserer AI-Serie, Die jüngsten raschen Verbesserungen im Bereich der natürlichen Sprache und der großen Sprachmodelle (LLMs) haben eine moderne und sprachbasierte Art der Kommunikation mit den Nutzern ermöglicht und einige Einschränkungen früherer Chatbots überwunden.
ION IQ nutzt diese Technologien, um einen Bot bereitzustellen, der die Interaktion unserer Kunden mit ihren Sicherheitsumgebungen verbessern soll. Er liefert Antworten auf Fragen zu Themen wie Kosten oder Sicherheitswissen - basierend auf dem spezifischen Bereich des Kunden.
Im Folgenden werden wir die Designprinzipien und die damit verbundenen Implementierungsentscheidungen für den Aufbau des ION IQ Bot untersuchen. Zu den beschriebenen Themen gehören Konzepte in Bezug auf Lokalisierung, Sicherheit und Datenschutz sowie Konsistenz - und wie wir diese erreichen wollen.
Durchführungsbeschlüsse
Konsistenz
Der ION-Bot wurde entwickelt, um eine der größten Schwächen von LLMs einzuschränken: Halluzinationen. Das Augmented Generation (AG) Muster, in Verbindung mit unseren Implementierungsentscheidungen, begrenzt die Möglichkeit von Halluzinationen und blockiert Fragen, die über den Rahmen hinausgehen.
Das AG-Muster zwingt unseren Bot, sich auf die Entwicklung von Eingabeaufforderungen zu verlassen, um alle für die Beantwortung von Fragen erforderlichen Informationen zu enthalten. Die Prompts werden sorgfältig ausgearbeitet, um diese Informationen effektiv zu nutzen und sie an das vorab trainierte Sprachmodell weiterzuleiten. Das bedeutet, dass keine Feinabstimmung oder Nachschulung des Modells erforderlich ist, um Antworten zu produzieren oder den Dienst zu verbessern. Das Modell, mit dem unser Bot arbeitet, ist das bekannte1 GPT-3.5-Turbo. Dieses Modell kombiniert eine hohe Ausführungsgeschwindigkeit mit hoher Zuverlässigkeit und einem starken Fokus auf strukturierte Eingabeaufforderungen, die unseren Anforderungen entsprechen.
Eine Voraussetzung für den Aufbau einer modernen Chatbot-Erfahrung ist die Möglichkeit, komplexe Aktionen durchzuführen, die das Sammeln externer Daten zur Beantwortung von Fragen beinhalten. Diese Anforderung macht einzelne LLM-Aufrufe unzureichend. Wir setzen auf das Konzept der Chains, um solche Fähigkeiten bereitzustellen. Eine LLM-Kette enthält einen oder mehrere LLM-Aufrufe und zusätzliche Aktionen, die sequentiell ausgeführt werden. Ein Beispiel: Die Beantwortung einer Frage zum aktuellen Wetter erfordert zusätzlich zu mindestens einem LLM-Aufruf eine Echtzeit-Datenquelle, um eine menschenähnliche Antwort zu erzeugen.
Um die gewünschte Konsistenz zu gewährleisten, stützt sich der ION Bot auch auf das Konzept der Agenten. Mit Hilfe von Agenten kann der LLM entscheiden, welche Kette (oder welches Tool) für die Beantwortung bestimmter Fragen besser geeignet ist, indem er deren Absicht und relevante Eingabeinformationen ermittelt. Dieses Konzept bietet eine zusätzliche Ebene der Kontrolle darüber, wann welche Aktionen ausgeführt werden. Um solche Agenten zu erstellen, haben wir uns für ein Open-Source-Framework namens Langchain2 mit umfangreichen Möglichkeiten und einer großen Entwicklergemeinschaft.
Lokalisierung
Der ION IQ Bot benötigt Zugang zu Informationen über die Umgebung unserer Kunden, um aussagekräftige Antworten geben zu können. Solche Daten werden bei Bedarf abgerufen und auf der Grundlage des AG-Musters in den LLM eingespeist.

Darüber hinaus benötigt der ION Bot Zugang zu:
- Das LLM: das Gehirn des Dienstes
- Ein Kurzzeitgedächtnis, das für Folgefragen benötigt wird
- Ein Sprachdetektor zur Beantwortung von Fragen in der Muttersprache des Kunden
- Eine Abfragebibliothek für den Zugriff auf Kundeninformationen, die zur Beantwortung von Fragen benötigt werden. D.h., Microsoft Sentinel Vorfälle und Nutzungsdaten
- Eine Wissensdatenbank mit Ontinue-Expertise und kuratiertem Microsoft-Sicherheitswissen.
Die Bereitstellung von Fachwissen aus einer umfangreichen Wissensbasis erfordert effiziente Methoden zur Interaktion mit LLMs, die Längenbeschränkungen unterliegen. Wir stützen uns auf das Retrieval Augmented Generation (RAG)-Muster3 für eine solche Interaktion. Wie das AG-Muster stützt sich auch RAG auf Prompt-Engineering, um das Modell mit Kontextdaten zu versorgen. Dieser Kontext wird durch die Suche nach den relevantesten Informationen (Dokumenten) in Bezug auf die Frage gewonnen. Zu diesem Zweck verwenden wir Vektorspeicher, die es uns ermöglichen, den Abstand zwischen der latenten Darstellung (oder Einbettung) der Frage und den Dokumenten zu berechnen. Dies ist der Abstand, in dem das relevanteste Dokument einer relevanten Antwort am nächsten ist.
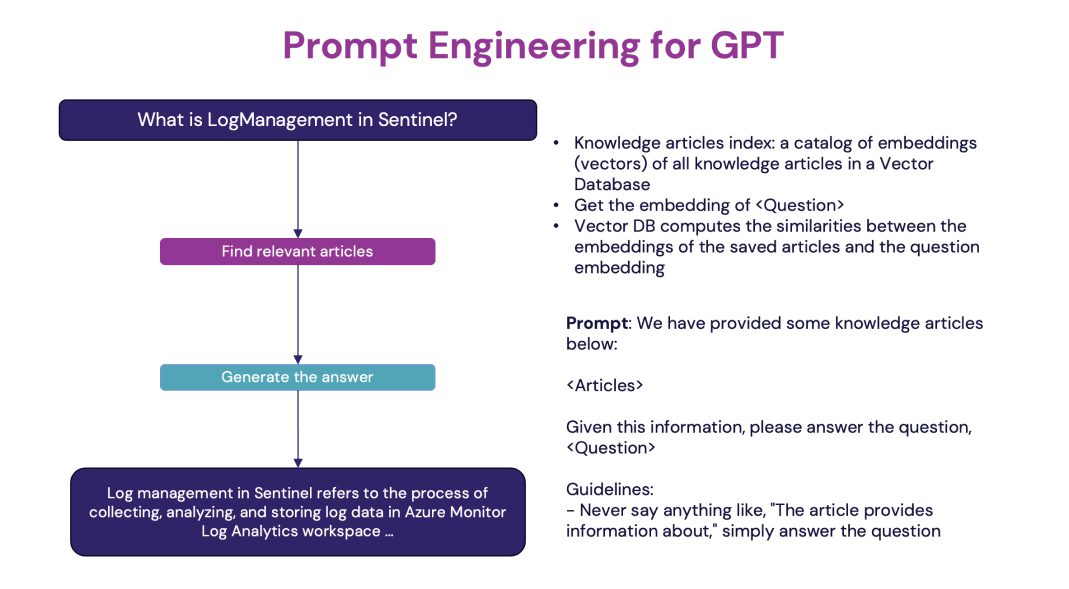
Datenschutz und Sicherheit
Unser Bot wurde so konzipiert, dass mögliche Datenlecks oder Datenschutzlücken vermieden werden. Unter Berücksichtigung dieser Anforderungen haben wir Azure OpenAI als Infrastruktur für die Bereitstellung unseres Sprachmodells gewählt.
Azure OpenAI stellt sicher, dass die Modelloperationen zustandslos sind, d. h. während der Inferenz werden keine Daten gespeichert, und während der Modelloperationen verlassen keine Daten die Servicegrenze. Es handelt sich um einen Cloud-nativen Dienst, der alle in Azure angebotenen Sicherheitsfunktionen bietet und in GDPR-Regionen eingesetzt werden kann, um die Compliance-Anforderungen unserer Kunden zu erfüllen. Dieser Dienst bietet auch Zugang zu hochmodernen Sprachmodellen, die von einem führenden Akteur im Bereich der KI, OpenAI, entwickelt wurden.
Schlussfolgerung
In diesem Beitrag haben wir die Wahl von Azure OpenAI aus Gründen der Sicherheit und des Datenschutzes untersucht. Wir haben das AG-Muster und die Konzepte von Chains und Agents untersucht, um einen konsistenten Bot zu erstellen. Und schließlich sind wir in das Thema Lokalisierung eingetaucht, um vorzustellen, welche Daten erforderlich sind, um eine nützliche Erfahrung zu bieten, einschließlich eines Überblicks über das RAG-Muster und das Konzept der Einbettungen beim Umgang mit einer großen Wissensbasis. Alle unsere Entscheidungen zielen darauf ab, ein sicheres, modernes und lokalisiertes Erlebnis für unsere Kunden zu schaffen, während wir gleichzeitig versuchen, die Herausforderungen von LLM-basierten Diensten, wie Halluzinationen oder Performance, zu begrenzen.
Referenzen
1 GPT-3.5-turbo ist das Standard-LLM-Modell, das ChatGPT zum Zeitpunkt der Erstellung dieses Blogs betreibt.
2 https://python.langchain.com/
3 https://colabdoge.medium.com/what-is-rag-retrieval-augmented-generation-b0afc5dd5e79

Sergio Roldan
Datenwissenschaftler
Sergio Roldan ist Datenwissenschaftler bei Ontinue und verfügt über mehr als zwei Jahre Erfahrung in der Arbeit an Themen der Cybersicherheit und des maschinellen Lernens. Er kam zu Ontinue als Praktikant für seine Dissertation über Graph Neural Networks, die auf den Sicherheitsbereich angewendet werden. Sergio hat Vorträge auf Sicherheits- und ML-Konferenzen wie CRITIS und AMLD gehalten und einen Artikel in JCEN veröffentlicht. Er erwarb seinen Master in Cybersicherheit an den beiden Eidgenössischen Technischen Hochschulen (EPFL und ETHZ).